rel-me

This article is a stub. You can help the IndieWeb wiki by expanding it.
Using rel=me on a hyperlink indicates that its destination represents the same person or entity as the current page, which is a key building-block of web-sign-in, IndieAuth, and ✅ distributed identity verification.
indielogin.com uses rel=me links to enable signing into websites such as IndieWeb.org.
See the rel-me specification for more details.
Why
You should add rel="me" to hyperlinks on your home page to your other profiles to:
- 🪪 enable Web sign-in and IndieAuth using your own domain
- ✅ distributed verification of your home page and profiles
Web sign-in and IndieAuth allow you to use your domain as your identity, instead of depending on social media identities, and silo sign-in methods.
Distributed verification shows proof that an account on one site is under the control of the same person as another site.
For example:
- Mastodon will show your home page as verified (with a ✅ and green background) on your Mastodon profile, if your home page links to your Mastodon profile with
rel=me. - Huffduffer will follow rel="me" links to show your connected social accounts without you having to enter them individually.
- There is also a browser plugin built by
 Kevin Marks which allows for this same kind of distributed verification.
Kevin Marks which allows for this same kind of distributed verification.
How
How to use rel me
See:
How to on WordPress
See:
How to consume rel me
See:
FAQ
Should my rel-me be inside my hCard?
A: Another way of restating that is, should your rel="me" hyperlink also have class="u-url" and be inside your h-card? And the answer is:
A2: Yes it should, because it will enhance your h-card, and make it into a representative h-card, but it is not necessary for rel=me to work with indieauth.
Follow-up Q: This on my blog but it’s not actually what I use for my main indieauth, should it still be setup like that?
Follow-up A: Because it is on your blog, you're likely using that URL as your p-author h-card URL. Thus making sure it has a good representative h-card is a good idea
Can I add rel-me to non-profile pages?
You should not add rel-"me" to pages that doesn't represent the same user as the profile the rel-"me" links to.
One should only add rel-"me" to pages that is seen as representing the same user as the profile it links to. Such pages can be the home page of a single user site or the author pages of a multi user site.
rel-author is often what one wants instead when linking to a profile page from non-profile pages.
Implementations
- PHP indieweb/rel-me package has functions for getting rel=me URLs on a site, securely deriving profile URLs and securely matching silo backlinking URLs against profile URLs
- Ruby relparser.rb (part of IndieAuth.com) contains functions for doing the same sort of stuff
- Python
- relme.py (part of Ronkyuu) contains functions to discover rel=me URLs on a site, generate normative URLs for both profile and resource URLs and to confirm that a resource URL is authoritative for a given profile URL.
- IndieWeb Utils implements a
get_valid_relmeauth_linksfunction that discovers both one-way and bi-directional rel me links. View the documentation for this function.
Browser Support
verify-me
verify-me by Kevin Marks is a browser extension that checks all rel="me" links for being reciprocal, doing distributed verification.
 Martijn van der Ven added support for local verification in a since merged fork: verify-me-locally
Martijn van der Ven added support for local verification in a since merged fork: verify-me-locally
rel-me verifier
rel=me verifier by Bill Doyle is a userscript inspired by the verify-me extension.
Streetpass
Streetpass is a browser extension that helps you find people's Mastodon profiles by adding them to a list when you browse a site with rel-me links.
Software Support
Mastodon
Mastodon supports a rel="me" URL on profile pages and thus on modern Mastodon instances by default.
Kevin Marks added verified links on his Mastodon.social account. The following information is listed on every profile page:
You can verify yourself as the owner of the links in your profile metadata. For that, the linked website must contain a link back to your Mastodon profile. The link back must have a rel="me" attribute. The text content of the link does not matter.
To add rel=me links to Mastodon:
- Click on the cog icon to go to Settings
- Click on Edit profile
- Copy the link to Mastodon under the verification section
- Go to your website your website
- Add the link to Mastodon containing the
rel="me" - Go back to your Mastodon profile
- Add a link to your website in the metadata section
- To add a link to GitHub just add a link to your Mastodon account on your GitHub profile by editing the url in the settings.
PixelFed
PixelFed supports rel="me" URL on profile pages since 2018 September.
- https://mastodon.social/@dansup/100726520814958974
- "Mastodon implementing rel=me?
Wicked! Support landed in pixelfed just last week. #indieweb https://pixelfed.social/dansup" @dansup September 14, 2018
- "Mastodon implementing rel=me?
MediaWiki
MediaWiki extension implementation:
Service Support
Keybase
Keybase has supported rel="me" on profiles since 2014-06-23! E.g.
micro.blog
Micro.blog includes rel="me" on any html page.
 Greg McVerry included rel=me links in his h-card on his micro.blog about me page. To add a link with
Greg McVerry included rel=me links in his h-card on his micro.blog about me page. To add a link with rel="me":
- Click on post
- click on pages
- Create a new page called "About Me"
- Add links to other places on the web you control and remember the
rel="me"
IndieLogin
IndieLogin supports consuming rel="me" for identity and login services via its implementation of RelMeAuth
omg.lol
omg.lol supports publishing rel="me" on public pages by default.
Wikipedia
Per https://wikis.world/@wikipedia/110396865170645710:
- "It's now possible to mark links to your #Wikipedia user page as verified on Mastodon! Documentation: https://www.mediawiki.org/wiki/Special:MyLanguage/Help:Extension:RealMe
This was developed and implemented by @taavi who wrote it as a #MediaWiki extension, named "RealMe". It's open source (like all of the Wikipedia software) and can be used on any MediaWiki wiki: https://www.mediawiki.org/wiki/Extension:RealMe" @wikipedia May 19, 2023
How to:
- Go to your https://en.wikipedia.org/wiki/Special:Preferences
- Scroll down to where it says:
User page
URLs to external profiles: - Enter your personal site URL with full
https://prefix etc. e.g. https://example.com - Save
View source on your User: page and you should now be able to find a link like:
<link href="https://tantek.com/" rel="me">(from https://en.wikipedia.org/wiki/User:Tantek)
Threads
Threads supports bidrectional rel=me, both publishing rel=me to your personal site on your Threads profile, and parsing that personal site for a rel=me inbound link to Threads. Threads displays an icon of two arrows (⇄) next to your personal site link when it confirms the two-way link (may take up to a day). Hovering over the ⇄ icon shows a tooltip: "Two-way link".
Threads announced outbound rel=me support 2023-08-09:
"We’ve also rolled out Threads support for rel=me links to help you verify your identity on platforms like Mastodon. You can now add your Threads profile link on supported platforms to verify your identity." https://www.threads.net/@mosseri/post/Cvu2eXurRbB
and inbound rel=me support 2025-02-06:
my latest favorite hidden feature.. two-way link verification on your link in biowe only supported outbound rel=me links previously. now we support the inbound direction, so you can prove two-way ownership of your threads profile link with the double arrow icon next to the URL.instructions to do so below (🧵 1/3) https://www.threads.net/@0xjessel/post/DFvd8k4SEGq
How to:
- Open Threads app
- Tap the 👤 icon in the bottom right
- Tap the (Edit Profile) button
- Tap in the [Link] field, enter your domain, and tap "Done" and "Done"
Articles/posts:
- 2023-08-09 The Verge: You can now verify your Threads profile on Mastodon
- 2023-08-10 The Verge: How to verify your Threads account using your Mastodon profile
- 2023-08-10 TechCrunch: Meta adds ability to verify your Threads profile on Mastodon
- 2023-08-10
 Ben Werdmüller: https://werd.io/2023/how-to-verify-your-threads-account-using-your-mastodon-profile
Ben Werdmüller: https://werd.io/2023/how-to-verify-your-threads-account-using-your-mastodon-profile - 2023-08-22
 Tantek Çelik: https://tantek.com/2023/234/t1/threads-supports-indieweb-rel-me
Tantek Çelik: https://tantek.com/2023/234/t1/threads-supports-indieweb-rel-me
Gravatar
Gravatar supports rel-me for account verification since ????-??-??
Letterboxd
Letterboxd supports rel-me since at least 2023-12-07
E.g. this Letterboxd profile:
has a rel="me" link to
Silo Details
Twitter no longer seems to include a rel="me" URL on profile pages.
Twitter includes a rel="me" URL on profile pages, but the URL is hidden behind their t.co redirection service. Example as per 2018-09-19:
<a class="u-textUserColor" target="_blank" rel="me nofollow noopener" href="https://t.co/UT1OXws8A5" title="https://vanderven.se/martijn/">vanderven.se/martijn/</a>
There are a few ways to solve checking whether Twitter has a backlink:
- follow the RelMeAuth algorithm that specifies to follow one redirect; or
- resolve all
rel-meURLs in their entirety; or - use Twitter specific parsing and extract the full URL from the
titleattribute.
Note that for 1 & 2 there might be issues with requesting the t.co URL. For certain user agents it will not result in an HTTP redirect, but will instead just offer an HTML redirection page.
Some implementations are specifically setting dummy user agents to get around this problem: e.g. this commit on verify-me-locally.
Requests
rel=me and relmeauth
(to be reviewed)
This is my (who?) current interpretation - so people can correct and critique it rather than assert any truthiness to this.
rel=me is intended to mean that the destination represents "the same person as" the current page.
However, it also serves a dual purpose when used for RelMeAuth based authorization. Here, a rel=me link really wants to mean the destination "can claim control over" the current page. You could instead pretend there's a "rel=is-controlled-by" tag to distinguish the two contexts.
Why does this distinction matter?
A page such as github.com/kbsriram cannot (legitimately) claim a rel=me link to github.com. Clearly, the site "github.com" does not represent a "person who is the same as" github.com/kbsriram
However, the root domain on every website does control all its sub pages, so in fact, github.com/kbsriram has an implicit "rel=is-controlled-by" to github.com, but it does not have a rel=me link to github.com
This distinction matters when finding rel=me closures in the two contexts of identity consolidation and relmeauth based authorization.
To make this concrete, let's assume we have these three pages, with these rel=me links on them.
myfamily.example.com/tommy [rel=me] -> {plus.google.com/+tommy}
myfamily.example.com [rel=me] -> {plus.google.com/+tommy}
plus.google.com/+tommy [rel=me] -> {myfamily.example.com/tommy}
Consolidating Identities use case
Given a page, find me all the pages who are "the same person as" the current page.
The approach is to recursively follow all the rel=me links from the starting page, and return only that subset which is within any loop of rel=me links that include the starting page.
This is so that only a group of mutually verifying pages are returned, or anyone could simply claim they were https://plus.google.com/+LinusTorvalds by putting a rel=me link on their page.
If we started from myfamily.example.com/tommy, we'd get back
{myfamily.example.com/tommy, plus.google.com/+tommy}
as the pages who "are the same person as" myfamily.example.com/tommy
And If we started from myfamily.example.com, we'd get back just
{myfamily.example.com}
Web sign-in
Web sign-in is relmeauth based login.
Given an page, find me all the pages "who can control" the current page. The "current page" is used as the username, and one of the controlling pages is used to login the user, say through OAuth.
In principle (though implementations don't necessarily do this) the approach is still similar, but now there is an implicit assumption that any subpage of a domain is controlled by the bare domain.
In particular, the set of all pages "who can control" myfamily.example.com is
{myfamily.example.com, plus.google.com/+tommy, myfamily.example.com/tommy}
because of the implied link that myfamily.example.com/tommy is-controlled-by myfamily.example.com
Edge Cases
Edge cases are questions or issues brought up typically by only one (or a small number) of people, and in practice affect very few people. We document them anyway in the hopes of helping out those few, yet apart from the broader #FAQ, keeping the FAQ focused on frequently asked questions (applicable to more people in general).
What About RDFa Problems
If you use RDFa and are having problems, note that RDFa redefines 'rel' attribute processing that is incompatible with the HTML(5) standards thus rel=me may produce unexpected results inside RDFa.[1]
There is a solution available in RDFa WG mail archives https://lists.w3.org/Archives/Public/public-rdfa/2014Oct/0005.html
Any non-CURIE (e.g. "me") will be ignored in a @rel if there is a @property attribute in the same element. Here is what I recommend to use, which simplifies your markup as you don't need to repeat the mailto:. Drop the @rel from the ul, and use something like this:
<ul vocab="http://schema.org/"> <li> <a rel="me" property="contactPoint" typeof="ContactPoint" href="mailto: perpetual-tripper@wwelves.org"><span property="name">email (smtp)</span></a> </li> </ul>
Articles
- 2018-04-26 Martijn van der Ven: The Real Deal About
rel="me"(archived)
See Also
- microformats
- web-sign-in
- IndieAuth
- verify-me
- verified
- rel registry
- https://glitch.social/@gcupc/100613354693156448
- "@kaniini
rel=me is the best way to do decentralized identity verification, as long as you are requiring DNS anyway, like AP does." @gcupc August 25, 2018
- "@kaniini
- thread on using rel=me for decentralized identity verification
- https://mastodon.social/@Gargron/100726489667811566
- "Okay I didn't mention what the "special attribute" was because I didn't want to alienate the non-dev audience, but I'm getting a lot of suggestions for complicated things, so yeah, I meant microformats rel="me", it's the simplest thing, why would you even bother with TXT records or public keys" @Gargron September 14, 2018
- https://mastodon.social/@Gargron/100726508288588883
- "@JonathanGerlach DNS doesn't work as well because not everyone knows how to edit DNS records. It's easy to put a rel="me" link in your tumblr bio, or drop in on your sharing hosting site, but it might not even be possible for you to edit your DNS records." @Gargron September 14, 2018
- XFN
- Distributed Verification 2016-09-22
- Rel-me, mastodon and browser plugins
- https://help.micro.blog/2017/web-site-verification/
- UI for parsing & viewing rel=me links from a site: https://rel-me.cc/
- backlink
- edgecases to avoid https://edoverflow.com/2018/logic-flaws-in-wot-services/
- https://twitter.com/simonw/status/1588563298597101569
- "The way Mastodon handles verification is smart: it uses rel="me" links and shows verified links on your profile page with a green background https://fedi.simonwillison.net/@simon" @simonw November 4, 2022
- ^
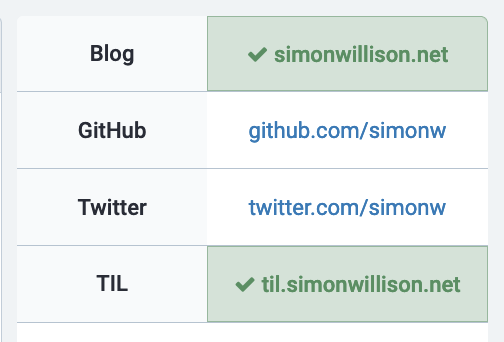
- Instructions for adding rel-me to WordPress for Mastodon verification: https://g13g.blog/2022/11/09/how-to-verify-your-wordpress-site-on-mastodon/
- "How to verify your WordPress site on Mastodon#mastodon #wordpresshttps://g13g.blog/2022/11/09/how-to-verify-your-wordpress-site-on-mastodon/" @georgehotelling November 9, 2022
- https://hci.social/@cfiesler/109406111320023346
- "Now that we're starting to see more impersonation accounts on Mastodon, a reminder that verified websites are a thing. It's not perfect, but implementable at the individual level, and this is how we know for example which of these is the real @stephenfry - and it's not the one with the meaningless checkmark. :)" @cfiesler November 25, 2022
- https://meta.trac.wordpress.org/ticket/6642 request to add rel-me to profile links on the WordPress.org profile page
- Article on using rel-me for verification on Mastodon: https://themarkup.org/levelup/2022/12/22/how-we-verified-ourselves-on-mastodon-and-how-you-can-too
- Browser add-on: https://streetpass.social/
- Washington Post journalist profiles now support rel=me: https://mastodon.social/@drewharwell/109830211615397520
- "The Washington Post now flags journalists' profiles as verified on Mastodon." @drewharwell February 8, 2023
- Mastodon support documentation: https://joinmastodon.org/verification
- Friendica shows a check mark next to a verified link on the user profile #12109 Verify homepage by checking for a rel-me link back to the user profile
- GitHub support of four rel=me links in profile: https://hachyderm.io/@derekprior/109790473003989772
- "You can now add up to four social account links to your GitHub profile which render with a sprinkling of formatting support for our most popular platforms. Yes, the resulting links links will satisfy Mastodon verification requirements when rendered.To get started, visit your profile and click the "Edit profile" button in the sidebar." @derekprior February 1, 2023
- A novel consuming implementation: Subscribing to the blogs of people I follow on Mastodon
- https://social.coop/@eloquence/111135380251540525
- "This is a really nice touch recently added to Mastodon: when you search for profiles, it now shows you if they've completed link verification for a domain. All the more reason for folks who want to verify their identity on Mastodon to do so. See https://docs.joinmastodon.org/user/profile/#verification for docs." @eloquence September 27, 2023