backfeed
Backfeed is the process of syndicating interactions on your POSSE copies back (AKA reverse syndicating) to your original posts.
Why
We POSSE to make it easier for our friends and others to read our posts.
The point of implementing backfeed is to similarly make it easy for those same people to interact with those POSSE copies in a way that makes it back to the original, thus make it easier for you, the author of those original posts on your indieweb site to read their comments, and view other interactions.
You should implement backfeed to:
- Read more comments on your posts: all in one place, indieweb comments, and comments on your POSSE copies.
- See likes & reposts of your posts. Again, by aggregating indieweb likes with likes/favorites of POSSE copies into one place, you can more quickly get an overview of all those reactions.
- Better save comments, likes, reposts. In short: greater longevity of interactions. By copying those interactions to your own post permalink, you save them from numerous silo-content-loss scenarios from malevolent censorship to eventual site-death.
- Have higher quality discussions: get better signal to noise than what some silos allow. E.g. Twitter has no mechanism to delete (or disassociate) comments (@-replies) on your posts (tweets). They only have mute and half-implemented block which hides them from you, however everyone else still sees any abusive or noisy @-replies. You can moderate those as you see fit on your own site, thus improving the comments overall on your posts as compared to what silos allow for.
How
There are two general approaches to implementing backfeed from silos.
Use a silo API
You can use silo APIs to either be notified about interactions (via webhooks), or poll your POSSE copies for interactions, and incorporate them into your posts. Some APIs have better functionality for this than others.
Specific "how to backfeed" documentation per silo API:
Twitter APIs to use for getting @-replies etc. on Twitter to your Twitter POSSE copies:
- Search for
DOMAIN filter:linkswithresult_type=recent. See example code here (and continued here). Only returns recent results, but otherwise works ok. - There's no official way to get replies to a given tweet. If it's not too old, though, you can search for @-mentions of the original tweet's author, then look through the results for any whose
in-reply-tofield points to the original tweet. See example code here. - Otherwise, there's the unreliable, undocumented, unofficial 'related_results' endpoint.
See:
Flickr
Flickr has direct APIs for this:
Use a backfeed proxy
Alternatively, you can support receiving webmentions, and then use a proxy that calls silo APIs for you, and sends you webmentions for each silo interaction. E.g.
IndieWeb Examples
Singpolyma
singpolyma syndicates posts out to Twitter and runs a cronjob that polls the replies/mentions (authenticated) API endpoint to pull in responses. (since ????-??-??)
Ryan Barrett
 Ryan Barrett uses Bridgy (see below) to backfeed comments, likes, and reposts from the silos to his own site since 2011-12-02:
Ryan Barrett uses Bridgy (see below) to backfeed comments, likes, and reposts from the silos to his own site since 2011-12-02:
E.g. see Facebook and Twitter comments here:
See Facebook, Twitter, G+ comments, likes, +1s here:
Basil
Basil syndicates posts to Mastodon and uses the API on his instance to pull replies back to his site.
Björn Schießle
Björn Schießle also uses the Mastodon API to pull replies back to his site. Example: https://www.schiessle.org/articles/2019/04/05/the-power-of-workflow-scripts/
Mastodon API: https://notes.abhinavsarkar.net/2023/mastodon-comments
Michael Thomas
Mastodon API: https://blog.thms.uk/2023/02/mastodon-comments
Kristof Zerbe
Kristof uses Mentions-United for client-side retrieving interactions from multiple providers on his blog kiko.io, depending on the syndications defined in the frontmatter of the posts.
Other Examples in the Wild
Journalism
- Buzzfeed on 2017-02-17 announced a backfeed related experiment "called 'Outside Your Bubble,' an attempt to give our audience a glimpse at what’s happening outside their own social media spaces." An example of the new feature integrated into their site was also provided in the article. (See also filter bubble.)
Science Communications
- BioRxiv is using backfeed of Tweets about a scientific article to provide "social proof" of the reach and influence of scientific journal articles. See also: Let's make science metrics more scientific.
- In some sense Altmetric operates like a commercial version of Bridgy for the scientific publishing community.
- Similar to Altmetric, Plum Analytics, a subsidiary of Elsevier, offers some backfeed and online mention analytics.
- Example of analytics for the SSRN article Pulling the Goalie: Hockey and Investment Implications
Service Implementations
Bridgy
brid.gy is a service that sends webmentions for comments/replies, likes, reposts, and mentions on Twitter, Instagram, Flickr, and GitHub (and formerly Facebook and Google+). It uses original post discovery to find target links for the webmentions. GitHub repo here.
Salmon Unofficial
salmon-unofficial was an older, unmaintained alternative to Bridgy that used the Salmon protocol instead of webmention. It discovered original source sites via LRDD, WebFinger, and XRD, as specified by Salmon. GitHub repo here.
Altmetric
Altmetric operates somewhat like a proprietary commercial version of Bridgy for the scientific publishing community. It provides data via API for mentions of research on other platforms including Twitter, Weibo, Reddit, Facebook, Wikipedia, Google+, LinkedIn, Pinterest, and other research related platforms as well as blogs.
OwnYourSwarm
OwnYourSwarm is a service that sends your Swarm checkins to your website via Micropub, as well as sending webmentions for comments and likes on your checkins.
Server Implementations
WordPress Plugins
- Social - This was shut down at the end of 2016, and due to a middle-ware proxy, may never function again.
- NextScripts SNAP
- Jetpack Publicize is great, but doesn't yet implement backfeed.
Hugo, for Mastodon
Client Implementations
Mentions United
Mentions United is a JavaScript solution for retrieving available interactions in the browser while the page is loading, based on the syndications associated with the post. The project consists of a main script and two types of plugins: Provider and Renderer, for retrieving interactions from a specific platform and generating the desired HTML respectively.
Discussion
Storage, legal, data ownership, UX...
Do these responses belong on your indie page, at the original source of the content? There are storage, legal, data ownership, UX, and other questions.
- Yes:
- Gives people a choice about where to author their replies
- Enhanced UX (debatable depending on service used)
- Ease of use, low barrier of entry. Peter Shaw describes this well, notably the value and intuition of replying at the location source post, which is especially compelling for users who are less technical or willing to spend extra time and effort.
- Meets the majority of users who aren't technical or don't feel strongly where they currently are: in the silos.
- +1 barnabywalters
- +1 Ryan
- ...
- No:
- Generic, open systems such as pingback are preferable to backfeed from closed silos (although open response systems are another discussion entirely).
- Responders didn't choose to publish at the original source. In rare cases, this could cause legal problems.
- Imposes more overhead.
- May antagonize silos. They often try to prevent this kind of outward syndication of their data. One example (of many).
Also, many silos support private and semi-private posts: Twitter protected accounts, Instagram private accounts, Google+ circles, Facebook posts to just your friends. Replies to those posts are usually limited to the same audience, which means they generally should not be backfed to any publicly visible web page.
These (semi-)private replies could be backfed to a private post that's only visible to the same audience. Private posts aren't very widespread yet, though, especially not POSSEd to the same private audience, so we haven't really seen that in practice yet.
Moderation and spam
If the syndicated copy of POSSE'd content receives spam interactions (e.g. Twitter likes from fake bot accounts), this spam is carried over to the original page. Being undesirable, this might require manual action by the site owner, as backfeed implementations commonly don't have spam detection built in (e.g. incoming Bridgy backfeed replies cannot be processed by common content-based spam filters as the spam is the reply itself, not its content).
Possible approaches to dealing with this issue are:
- manual moderation
- not displaying backfeed from spam-prone sources at all
- verifying incoming replies by computing whether the Twitter user is e.g. max. 1-2 degrees away on the social graph
- queueing incoming backfeed replies in an approval queue
Vouch is promising for native IndieWeb moderation, but doesn't work for silos. It expects each user has their own domain, which generally isn't true on silos. Also, quality and behavior of users, posts, comments, moderation, etc on silos varies significantly from IndieWeb sites, and even across different silos. If you want to programmatically filter backfeed webmentions, we recommend special casing backfeed senders like Bridgy based on source URL domain, or individual silos or even individual silo users based on u-url domain and path.
Also see Vouch#Backfeed
Brainstorming
"pure web" backfeed
We've thought a lot about backfeed for silos and POSSE copies. How would backfeed work for "pure web" syndicated copies, ie pages that aren't the original post, but fully cooperate with web standards and indieweb protocols as much as possible? Here's a sketch.
Background
- 2010-02-03 backfeed first described online as a concept in conceptualizing #DiSo 2.0 but called "reverse syndication":
#8 reverse syndication of comments+tags+notes from said specific sites.
- 2010-10-06 POSSE+backfeed conceptual architecture (predating the terms)
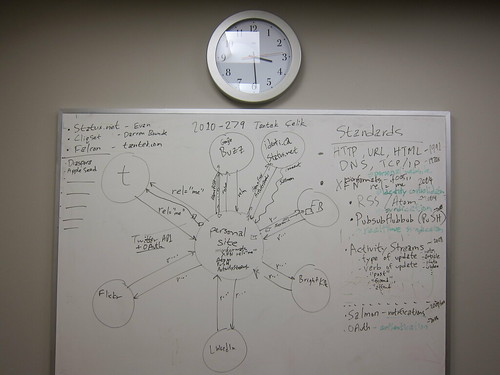
Note the arrows to/from the "Personal site" in the middle. Arrows outward are conceptually illustrating POSSE, while those returning, backfeed.
See Also
- interactions (comments, likes/favorites, reposts)
- POSSE
- webmention
- Manual Backfeed in the Blogosphere
- Why not: https://macwright.com/2022/09/15/hacker-news.html
I’ve learned some bad habits from Hacker News. I added _Caveats_ sections to articles to make sure that nobody would take my points too broadly. I edited away asides and comments that were fun but would make articles less focused. I came to expect pedantic, judgmental feedback on everything I wrote, regardless of what it was. [...] pushing away what I don’t like. Redirecting Hacker News links away from this website makes sense to me. Traffic to this website doesn’t pay my bills. Disengaged readers just looking for a hot take don’t return to my site, or recognize me when I write something else, or write blog posts of their own and bring new creativity to the indie web.
- How to, reverse syndication consideratinos: 2022-12-03
 Terence Eden: The ethics of syndicating comments using WebMentions
Terence Eden: The ethics of syndicating comments using WebMentions - https://graysky.app/blog/2024-02-05-adding-blog-comments
- https://snorre.io/blog/2023-08-19-atproto-bluesky-comment-system/