Webmention-brainstorming
This page is for Webmention brainstorming, issues, and an archive of past discussions that have been resolved.
Brainstorming
status page
The Webmention spec includes the possibility of creating a status page if processing a webmention asynchronously. This enables a sender to have a way to check on the status of whether their webmention is verified.
If a receiver returns a status page, the spec says to respond with HTTP 201 and a Location header, e.g.
HTTP/1.1 201 Created Location: http://aaronpk.example/webmention/DEhB9Jme
The contents and format of this status page are not specified, as there were no consuming cases implemented at the time of standardization. The goal of the status page is to give senders a way to know whether their webmention sending was successful or why it failed. People have implemented a variety of different ways this information is returned at the status URL.
Implementations
IndieWeb community members who have implemented either serving status pages or consuming them:
- webmention.io returns status pages that return either JSON or HTML depending on the Accept header.
- The HTML status page contains a header section with "Status: Success" or "Status: (error code)" depending on whether verifying the webmention was successful. Possible errors include: target_not_found, invalid_target, no_link_found
- If the Accept header includes application/json, then the JSON in the HTML page's "Debug info" is returned instead.
- This includes a property "status" set to "success" when successful, or one of the error codes above, as well as the source and target URLs, and the XRay-parsed result of the source URL to aid in debugging.
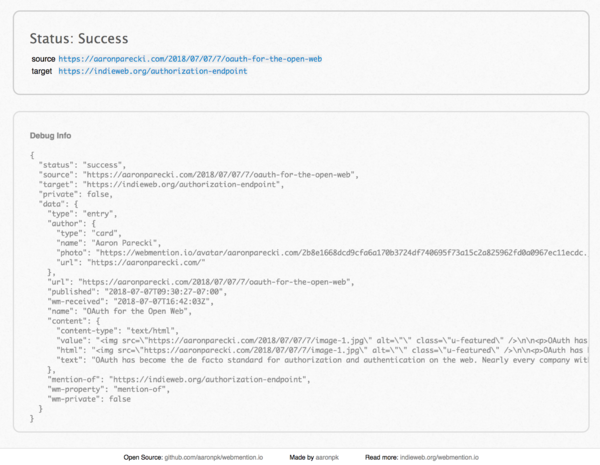

- Telegraph checks for a status URL when sending a webmention and makes that URL available in the interface when you check your history of sent webmentions

 Aaron Parecki in p3k version 1 (example URL: https://aaronparecki.com/webmention/rf2_14yA)
Aaron Parecki in p3k version 1 (example URL: https://aaronparecki.com/webmention/rf2_14yA)
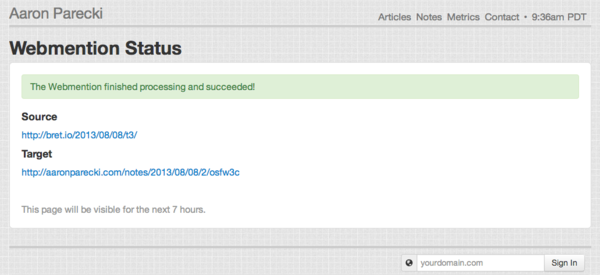
- Johnny Oskarsson (example URL: https://joskar.se/webmention/rgjnJ8)
 Ben Roberts (example URL: https://ben.thatmustbe.me/queue/123)
Ben Roberts (example URL: https://ben.thatmustbe.me/queue/123)
using x-forwarded-for to mitigate DDoS abuse
When verifying a webmention by checking the source site, include an X-Forwarded-For HTTP header in your request, with the value set to the IP address of the client that notified your server of the alleged webmention.
That is, to verify, do something like:
curl -H "X-Forwarded-For:$sender_ip" $source
where $sender_ip is the IP address of the incoming request that informed you of the webmention and $source is the source page of the alleged webmention. Then check the response to see whether a link to $target is present.
For more, see DDOS#Forward_originating_IP_address.
Note: WordPress is using X-Pingback-Forwarded-For to mitigate abuse of pingbacks. And IETF is also in process of standardizing a Forwarded header (with a more detailed semantics). If someone feels strongly, we could pick one of those or mint something new, but in the meantime, use X-Forwarded-For.
Asynchronous status polling
Asynchronous status polling could be achieved via the webmention receiver returning a LINK header with rel=status with a URL for querying the status of a specific pending webmention request.
Example:
LINK: <http://example.com/m/10> ; rel="status"
Then the sending of the webmention could poll that URL for updates on the status of that particular webmention.
- It's nice to reply to a webmention request with HTML including a link to the status location (particularly useful for mentions sent via a form). I would prefer to put the rel="status" on that visible link instead of the header Kylewm.com 19:07, 19 August 2014 (PDT)
Status Query Results
In order to distinguish between the layers of a request to the status page and the actual current status of the webmention, the page could return an additional header to explain that status of the webmention processing. This could be the same code that would have been returned if the webmention were just submitted.
Example:
HTTP/1.1 200 OK Webmention-Status: 202
This would say that the webmention is still in the state of "accepted" but has not processed yet. This also leaves the page body open to any formatting for the user's view.
Asynchronous status notification
Asynchronous status notification could be achieved by using a webhook in the initial webmention request.
I.e. in addition to:
- source=URL
- target=URL
add:
- callback=URL
to the webmention POST request.
Webmention receivers that support the callback URL could acknowledge that it will eventually send a POST to the callback by responding to the webmention request with either (tbd): a specific HTTP code, an HTTP header, or something in the body of the response.
The Webmention receiver would then send a POST request upon completion of processing of the webmention, with a "status" query parameter indicating the outcome of webmention processing. See "More status codes" below for possible values for that parameter.
Example payload sent to the callback URL:
source=URL& target=URL& status=200
Variable Response Body Problem
To deal with the variable response body problem:
- Make response body optional
- Send the error information in a response header, probably similar format to status
- E.G. X-Webmention: 16 Source URI Not Found or X-Webmention-Response: 17 Not Linking
- Re-use the semantics + error codes from the pingback spec [1]
propagation to a mobile device
To make webmentions more useful, it would be great if there was some way to have them propagate as notifications to whatever devices the user has setup to receive such notifications.
homepage webmentions
It is possible you may want a separate webmention endpoint to handle homepage webmentions
See: homepage: webmention to homepage.
retrying/error handling
Good retry logic can be hard, regardless of what you're doing, and webmentions are no exception. Here are some current practices we use to retry HTTP fetches for webmention endpoint discovery, sending webmentions, and fetching source pages to check backlinks.
- Bridgy gives up immediately on 4xx errors and DNS lookup failures. On other errors (mostly 5xx and connection failures), it retries 30s later, backs off exponentially down to once an hour, and gives up after 3d.
rate-limiting
An endpoint getting too many requests, potentially from a single source, should be able to communicate this to senders, asking them to retry later. (note that it might be necessary to rediscover the endpoint, maybe comparable to caching)
If a single sender is sending too many requests, HTTP 429 (Too Many Requests) seems like the appropriate response. In other cases, HTTP 503 (Service Unavailable) can be used to signal temporary failure. Both allow a Retry-After header to give a hint when new submissions are accepted.
- webmention.io sends 429[2], as does Skein [3]
The Webmention specification currently doesn't mention how responses other than 400 & 500 should be treated.
For senders that are directly triggered by a user that can not retry later automatically, it might make sense to displays those temporary errors differently to the user than more permanent errors (like a missing WM endpoint), prompting them to retry manually later.
Endpoint By Page on Same Domain
Pages that do not support webmentions should not advertise an endpoint, even if the domain in general does.
proof-of-work
Webmention spam is not (at time of writing) really a problem; it'd be nice to keep it that way. A proposal: add a hashcash-like "proof of work" to a webmention request. In essence, this is a calculation which takes a little time to do; not enough to impact an individual sender, but enough to make large-scale webmention-sending (i.e., spam) problematic.
epoch hashing
Proposed approach (suggestions from crypto people are welcome!)
In addition to the conventional parameters to a Webmention (i.e: source=http://source/article&target=http://target/whatever), also pass two new parameters, time=1417292519&nonce=5684712. The value SHOULD be generated as follows:
time: UTC Epoch timenonce: a value representingsha256("000000" + target + "-" + time + "-" + nonce).hexdigest()
The number of zeroes required can be varied before specifying this approach to “tune” the difficulty of creating a nonce; 6 zeroes takes some seconds on a reasonably modern machine.
An endpoint then checks that the code, whenever computed, actually begins with "000000" and that time is not too long ago (to prevent replay attacks; "not too long ago" is intentionally vague here because one must consider clock drift and so on).
2022-03-22  Jacky Alciné: Where do we get the value of
Jacky Alciné: Where do we get the value of time from? The request headers?
hashcash-for-vouches
Possible alternative: set up hashcash-for-vouches.com where one submits the proof of work to h-f-c.com and if it verifies, h-f-c then vouches for you as per Vouch. What should then happen is that if people generally agree that h-f-c is requiring a proper proof-of-work, everyone whitelists it. So it's all done on the back of Vouch, but it doesn't have Vouch's clique problem.
A working implementation of this is at Hash for Vouch and described in detail there and on kryogenix.org.
plain hashcash
Hashcash for Vouches seems like overengineering.
Why not just attach a hashcash to the webmention itself?
If you were sending a webmention from http://example.org/a to http://another.example.org/b, you'd take the target URL, calculate a hashcash for that URL, then send that as an extra parameter in the webmention.
To specify the hashcash bit level, we could use a meta tag like this:
<meta name="webmention-hashcash" content="20" />
If you get a hashcashed webmention and you do support it:
- check to see if it follows the expected text format of a hashcash and that it contains a URL you care about and/or control
- if it doesn't, treat it as if it has not been hashcashed (or discard it if the URL doesn't match)
- if it passes the expected format test, check the hashcash
- if it passes, post it to your site
- if it fails, discard it
If you get a hashcashed webmention and you don't support hashcash, simply ignore it.
Performance testing: https://gist.github.com/tommorris/d57178fd02ee991e8c08
webmention permalinks
Several individuals have implemented webmention status pages, but what about a permalink for the webmention itself?
verifying private webmentions
If you receive a webmention from a web page that requires authentication to access it, the normal webmention verification process will fail. What is the best way to have the webmention endpoint authenticate as the receiver's website to be able to fetch the private page?
checking endpoint once per domain/caching the endpoint
Currently the spec requires webmention discovery on every URL you want to send a webmention to. If your post links to three separate notes on the same website, for every webmention you need to check the note’s page to discover the correct endpoint even though these are likely to be the same. Would it be safe to assume only one endpoint per domain? (From IRC 2015-06-15.)
Notes from related IRC discussion 2016-04-11:
- bridgy caches endpoints per domain for 2 hours, timing of exponential backoff for retries means if an endpoint changes the webmention is still delivered later
- caching fails with sites implementing expiring endpoints as anti-DDOS/spam/CSRF measure
- caching implementations will likely send Webmentions for URLs that don't accept them, receiving HTTP 400 responses and creating "unnecessary" load on both sides. They should not use high error rates as indication that the receiver is defective.
- implementations should not cache negative discovery results -> just because one page on a domain does not support WMs and doesn't announce an endpoint doesn't mean there aren't other pages doing so.
- If an implementation caches the endpoint and receives a 400 error when sending to the cached endpoint, it SHOULD NOT treat that as a failure, and SHOULD go re-discover the endpoint. This allows senders to use cached endpoints for receivers that don't implement CSRF protection, and will not fail for those that do.
storage
![]() Tantek Çelik,
Tantek Çelik, Sandro Hawke and I (
![]() Shane Becker) discussed what to store (irrespective of how
one stores data, i.e. database, html+mf2, etc) one night after IndieWeb Summit 2016. This is what we came up with.
Shane Becker) discussed what to store (irrespective of how
one stores data, i.e. database, html+mf2, etc) one night after IndieWeb Summit 2016. This is what we came up with.
Store:
- source (url)
- target (url)
- datetime received
- validation state (pass/fall/pending/etc)
- datetime validated
- source blob (whole html payload or just a section of the html payload)
Then you should process that blob from the source. If you can learn additional information about the source's post type, you should store that (rsvp, photo, note, etc). Then process the blob for type specific properties.
Optionally store:
- source's post type
- source's post specific properties (either inline or in a referenced store (e.g., a photos table in a database)
Even after processing the source blob and saving parsed properties, you should keep the source blob in case you want or need to process it again in the future with some new understanding or new requirements.
sending status
Webmention senders may wish to keep track of the status of webmentions they send.
- ready to send - the post exists on your site, but you have not yet sent the webmention
- discovery
- no webmention endpoint was found
- a webmention endpoint was found
- request received
- the webmention endpoint accepted the request (returned 2xx)
- the webmention endpoint requested a vouch (returned 449)
- the webmention endpoint rejected the request because of rate limiting (returned 429)
- the webmention endpoint rejected the request for some other reason (returned 4xx)
- the request failed due to a server error (returned 5xx)
- webmention displayed - the target URL sent a webmention back to you after displaying your comment
"pure web" backfeed
We've thought a lot about backfeed for silos and POSSE copies. How would backfeed work for "pure web" syndicated copies that aren't the original post, but fully cooperate with web standards and indieweb protocols as much as possible? Here's a sketch.
First, on the webmention sending side, when a sender fetches a target link to perform webmention discovery, it could also look for a rel-canonical link. If one exists, it would then send a second webmention to that rel-canonical page, with the same source URL.
Second, on the receiving end, when an incoming webmention's target URL isn't found in the source page, the receiver should also look for known syndicated URLs, e.g. u-syndication links. If one is found, the receiver would then handle the webmention as if the source linked to original post URL.
receiving webmentions for POSSE copies
What do people think about receiving a webmention for a POSSE copy?
E.g. You post to your site, you posse to twitter, someone @-replies on twitter, and then they put that reply permalink into the "send a webmention" form on your original post permalink?
Kind of a semi manual backfeed without Bridgy that is.
Motivation: webmention to tweet posse copy was motivated by manual backfeed to add a reply to a posse tweet that Bridgy apparently missed (probably due to Twitter's flaky search API, which Bridgy has to use since they have NO REPLIES API)
See replies to the POSSE tweet copy of:
which do not appear as replies on the original post
Webmention extension
We could extend the webmention spec like this:
- when verifying the 'target' parameter, also check to see if it matches any of your POSSE copy permalinks, if so, treat it as a backfeed webmention to the original post of that POSSE copy
As this doesn't affect existing compliant implementations, it should be backward compatible.
It should also be an extension that sites can implement immediately and try experimenting with.
How to implement
One way to implement it would be something like:
- if target otherwise failed verification (per normal webmention processing), then
- if target is a permalink to a post on a silo that my site POSSEs to, then
- do original post discovery on target
- recheck to see if that is one of my posts (same as normal target verification)
- if so, use that as the verified target, like you would for redirect processing of a target URL
- if target is a permalink to a post on a silo that my site POSSEs to, then
receiving webmentions for syndicated copies
Some websites supports syndicating posts, in part or in full, such as Medium, Dev.to, Lobsters, Reddit, etc. Many of those also provide a commenting feature, which is one of the motivations for people to syndicate their posts there in the first place. Those syndication destinations could support webmention natively rather than having to build a third-party webmention proxy service to handle it like Bridgy. In that case, here are some thoughts on how those services could support webmentions to send comments back to peoples' original posts.
- Alice writes a blog post on her site, alice.example.com
- Alice copies the post to a community site, Dev.to, and enters the original post URL in the "canonical" field
- Optional: Alice includes a u-syndication link from her site to the copy on Dev.to (helps prevent Dev.to being used to send spam to other blogs)
- Bob writes a comment on the syndicated copy on Dev.to
- Dev.to displays the comment on the syndicated post
- Dev.to creates a permalink for the comment in order to send it as a webmention to Alice's original post, adding reply Microformats to the post
- Optional: Dev.to checks that the canonical URL does include a u-syndication link to the Dev.to copy (prevents Dev.to from sending webmentions to random websites)
- Dev.to includes the link to Alice's original post on the comment page (marked up as u-in-reply-to)
- Dev.to sends a webmention from the comment URL to Alice's original URL
- Alice's website parses the comment as a regular reply and displays it on her post
Here is the example markup for Dev.to showing what needs to be added in order to have a comment on Dev.to work as a webmention:
https://gist.github.com/aaronpk/85e4adc582aeb6add7876b9f5a006e42/revisions
Here is how a Microformats parser will see that page:
https://gist.github.com/aaronpk/784caabe2649b9c759e6afec80827145
Note on the optional steps: A simpler option could be to have Alice verify her domain once at Dev.to, then Dev.to will only send comments back to the canonical URL if the canonical URL is on the same domain. This is slightly less strict than checking every post, but means authors don't have to have the ability to link to syndicated copies.
fetching stored Webmentions
The specification doesn't have a means of presenting all of the Webmention stored in the endpoint. Something like this SHOULD be behind an authorization block. Adding a means of retrieval would give the implementation a more complete sense - moving away from a write-only endpoint into an endpoint that can give people a means of fetching all of their incoming Webmentions in a uniform and universal way across sites (and tools).
The benefits include:
- Allow people to build readers that have more intelligent resolution of notifications based on feeds
- This can be a case where a site returns a specific feed for a particular reader (or a set of them)
- Expanding the default library to handle said retrieval in a universal way
- Reducing explicit conflation with (and load on) Webmention.io since it's the most public Webmention server that also provides a means of fetching Webmentions stored
The cons:
- Without authorization, this allows everyone to read the list. This can also become a problem for static sites that wish to use this as a way to render notifications after-the-fact
- A unique read-only token can be used here to prevent malicious use (or reading otherwise protected content)
- This can require more logic regarding permissions for implementations and adding something like that retroactively can be quite tedious.
The request could look something like the following:
GET /api/indieweb/webmention HTTP/1.1
Host: jacky.example
Content-Type: application/jf2feed+json
Authorization: Bearer 1a2bc3d4e5
{
"items": [
{ ... },
{ ... }
],
"paging": {
"after": "xxxxx",
"before": "xxxxx"
}
}
The structure of the response would be very similar to that of the timeline response for Microsub.
Alternatives
Alternatives to webmention.
LINK verb
James Snell brings up a suggestion to use the HTTP LINK verb to send the webmention notification. This would remove the need to first make the discovery request to find the webmention endpoint, since it could immediately send the LINK request to the URL itself.
Problems with LINK verb:
- It's way less likely to actually get adoption using the LINK verb. The discovery step adds an opportunity to add a layer of indirection, which lets us separate the server that handles the webmention. While discovery is an extra step, but at the same time it provides a lot of benefits.
- For example, it wouldn't be possible to have a static HTML site handle the HTTP LINK request, whereas it could delegate to a webmention service by using the <link> tag.
- Additionally, some hosting environments may not provide a way to handle the LINK request where a normal POST would work instead.
Because of the benefits and flexibility the discovery step adds, we need to stick with it and can't use the LINK verb as cool as that might be.
http://aaronparecki.com/replies/2013/08/08/2/webmention
LDN
Issues
DDOS attack vector
Webmention, like Pingback, is a vulnerable vector for DDOS attacks. See DDOS for more discussion and proposed solutions.
3rd party tracking exploits
Third party visitor tracking (or possible exploit) via nocache icons. See [4] for details.
- Known implements a fix for this where icons are locally saved as of September 7, 2014. Ben is interested in other approaches.
client unsure can read response
Not specifying a required response format and/or structures of the response formats is problematic as a client can never be sure they’ll be able to read the response.
- Fortunately, as Aaron Parecki noted, if there is an error, knowing exactly what caused it isn’t really very helpful apart from debugging, where the response will be read by a human anyway
- Rough consensus seems to be to default to a plantext error/success message, or if an accept header is given then maybe serialise it as requested, e.g. HTML or JSON. [5] Use case for HTML is in-browser sending --Waterpigs.co.uk 08:58, 22 October 2013 (PDT)
should bookmarks send webmentions
Should bookmarking (i.e. publishing a bookmark post) send a webmention? What if there are 1000's of bookmarks? how do you distinguish between normal links and bookmarks? - http://indiewebcamp.com/irc/2013-06-11#t1370966945
- I think bookmarking should yes, just as favorites and likes do. - Tantek 14:53, 13 August 2013 (PDT)
- As of 06-2017, several sites show bookmarks similar to likes, e.g. in facepiles
asynchronicity
Asynchronicity: a server may want to queue webmentions for source retrieval processing and do that asynchronously with the request. It's not always practical or advisable to handle all that processing in the actual HTTP POST thread. Thus receivers of webmentions must not be required to return no_link_found errors. - Tantek 14:53, 13 August 2013 (PDT)
repeat webmentions not an error
Updates: it's acceptable to send a repeat webmention, e.g. for updating or deleting comments. Thus the already_registered error must not be required, and should likely not even be an error in the first place. - Tantek 14:53, 13 August 2013 (PDT)
de-duplication
De-duplication (AKA de-duping deduping): replies and other responses are often duplicated in different places, e.g. via backfeed of POSSEd replies by Bridgy. Ideally, recipients should try to de-dupe webmention sources, preferring an original post.
- See: deduplication: How to deduplicate responses for more.
prefer original posts
prefer original posts - an alternative to implementing de-duplication is to simply always prefer original posts (replies) rather than their POSSE copies. You can implement this by:
- always do original post discovery on the "source" URL
- if there is an original post,
- use it instead of the source URL.
- thus: if/when your post receives Bridgy webmentions of POSSE copies of replies, you can find, retrieve, and display the original replies instead (i.e. treat it as if you received a webmention for the original).
- if you also receive a webmention for the original later (or before), you merely treat it as an update webmention using your existing update handling code path.
bad interpretation of h-feed source
- if the source URL contains multiple posts where only one references the target post (e.g., a homepage h-feed, sent accidentally or "maliciously"), target may interpret it as many comments (see [6] for an example)
- mitigation: webmention receivers should look for a backlink in the first h-entry on a given source page only.
Resolved Discussions
rel webmention addition to registry
- rel=webmention should be added to the HTML5 rel registry (supercedes/obsoletes IETF/IANA 'Web Linking').
- I'll take this up if there is enough consensus that we need it. I prefer the current URL based rel because it can be followed easily to get more info. Www.sandeep.io 06:08, 30 June 2013 (PDT)
- I'm happy to draft-up a rel-webmention spec and add it to the HTML5 rel registry if we decide we want this. Also ok with just keeping the URL for now. - Tantek 17:46, 30 June 2013 (PDT)
- rel=webmention is now registered in the HTML5 rel registry, and points to webmention.org as the spec. - Tantek 14:32, 13 August 2013 (PDT)
- Let's have rel=webmention supersede the .org URL value as rel=webmention is shorter, more readable in rel values / HTTP headers, and follows more standard term based rel value naming conventions. - Tantek 21:40, 17 October 2013 (PDT)
- +1 Jeremy Keith per [7]
- rel=webmention in the rel registry now points to this wiki as living spec. - Kevinmarks.com 22:41, 26 November 2015 (PST)
- I'll take this up if there is enough consensus that we need it. I prefer the current URL based rel because it can be followed easily to get more info. Www.sandeep.io 06:08, 30 June 2013 (PDT)
rel-webmention on <a> tags
Does it make sense to allow rel=webmention on anchor tags in addition to link tags?
- pro: wordpress.com (and maybe other hosted platforms?) prevent users from adding custom <link>s, but allow <a>s
- con: webmentions are basically machine-only; no user-facing data
- pro: GET request to webmention endpoint could return a helpful page with a link to webmention ("visible endpoint that teaches" [8])
- See this pull request to the webmention spec
These libraries and implementations support <a> webmention endpoint discovery
- PHP: mention-client library [9]
- Ruby: webmention gem [10]
- Python: webmention-tools [11]
- Python: Red Wind [12]
- ...
These webmention endpoints show human-friendly information, when visited with a GET request
- Aaron Parecki was already doing this [13]
- Webmention.io has links to webmention and a little bit dated copy referring pingback.me [14]
- Barnaby Walters displays a friendly page that includes a form for sending general webmentions [15]
- Kyle Mahan added a landing page like Aaron's [16]
- ...
More status codes
Synchronous webmention receivers should return the following status codes:
- 200 OK - the webmention was somewhat processed (i.e. preconditions checked out), but any of the following conditions may apply:
- 202 Accepted - the webmention is still queued for processing
- 400 Bad Request - for any of the following conditions:
- Source URL not found
- Specified target URL not found
- Source URL does not contain a link to the target URL
- Specified target URL does not accept webmentions
Asynchronously:
Similarly, in an asynchronous interaction, the callback webhook should include a "status" URL query parameter with the status codes noted above.